My article “Machine learning systems and intelligent applications” has recently been accepted for publication in IEEE Software and distills many of the arguments I’ve been making over the last few years about the intelligent applications concept, machine learning on Kubernetes, and about how we should structure machine learning systems. You can read an unedited preprint of my accepted manuscript or download the final version from IEEE Xplore. The rest of this post provides some brief motivation and context for the article.
What’s the difference between a machine learning workload and a machine learning system? Once we have a trained model, what else do we need to solve a business problem? How should we put machine learning into production on contemporary application infrastructure like Kubernetes?
In the past, machine learning (like business analytics more generally) has been a separate workload that runs asynchronously alongside the rest of a business, for example optimizing a supply chain once per quarter, informing the periodic arrangement of a physical retail store based on the prior month’s sales and upcoming product releases, identifying the characteristics of an ideal customer in a new market to inform ongoing product development, or even training a model to incorporate into an existing application.
Today, we often put machine learning in to production in the context of an intelligent application. Intelligent applications continuously learn from data to support essential functionality and thus improve with longevity and popularity. Intelligent applications are interesting for many reasons, but especially because:
- in many cases they couldn’t exist without machine learning,
- they are developed by cross-functional teams including data engineers, data scientists, and application developers – and thus involve several engineering processes and lifecycles in parallel: the data management pipeline, the machine learning discovery workflow, the model lifecycle, and the conventional software development lifecycle, and
- they are deployed not as separate workloads but as a single system consisting of compute, storage, streaming, and application components.
While the first and second points have serious implications for monitoring, validation, and automated retraining, the last point may be even more interesting: in contrast to legacy architectures, which had application infastructure running in one place and a separate analytic database, compute scheduler, or colocated-storage-and-compute cluster elsewhere, intelligent applications schedule all components together in a single, logical application-specific cluster, as in the following figure.
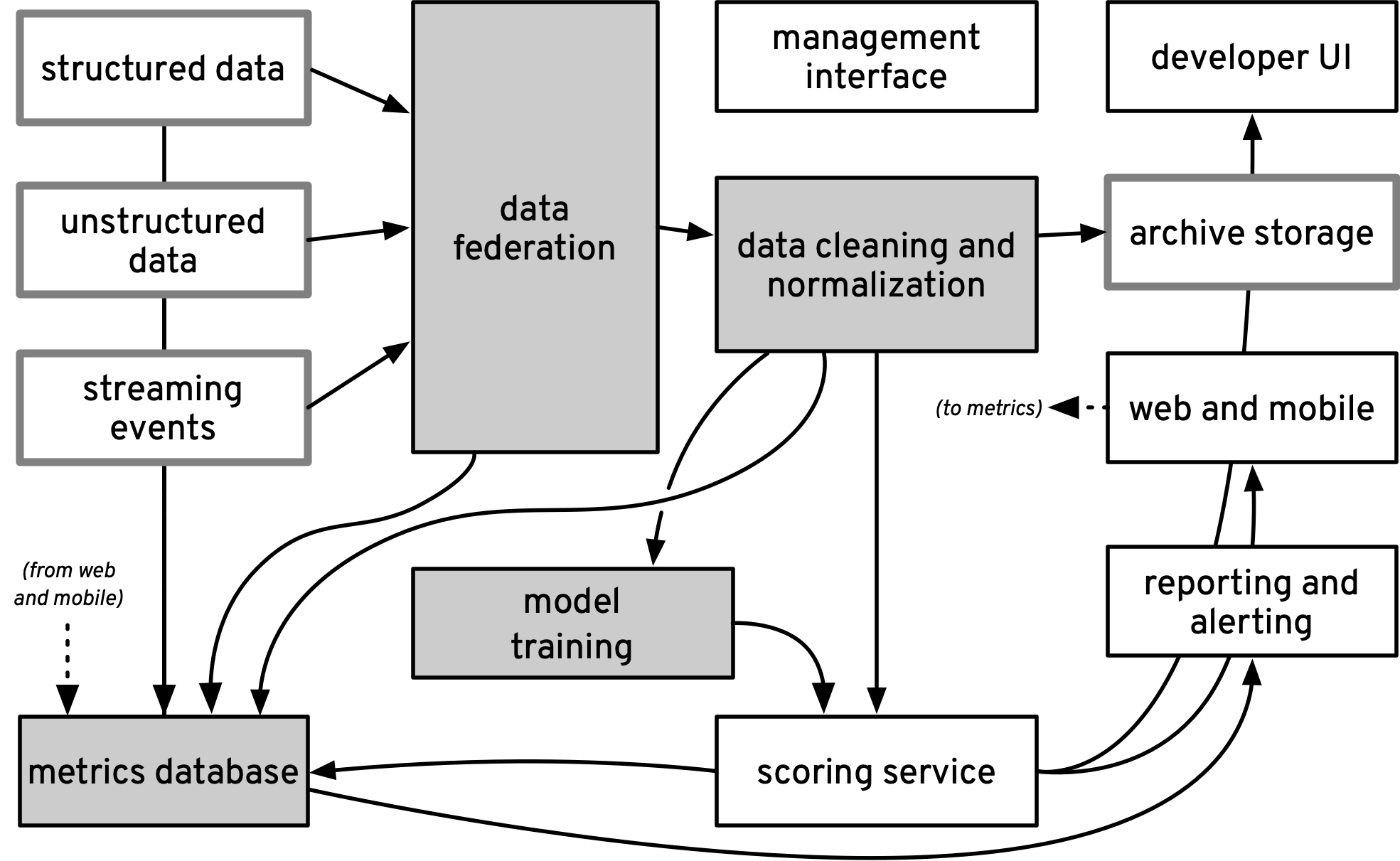
This architecture is possible because Kubernetes is flexible enough to orchestrate all of these components, but it is necessary because much of the complexity of machine learning systems appears not in the components themselves but in their interactions. The intelligent applications concept helps tame this complexity by enabling us to manage and audit all intelligent application components — controllers and views, data pipelines, predictive models, and more — from a single control plane.
To learn more, check out “Machine learning systems and intelligent applications” (in preprint or final version) and please let me know what you think!