The complexity of machine learning systems doesn’t subsist in the complexity of individual components, but rather in their orchestration, connections, and interactions. We can thus think of machine learning systems as special cases of general distributed systems. Furthermore, it’s relatively easy to argue that machine learning systems can benefit from general-purpose distributed systems infrastructure, tools, and frameworks to the extent that these make it easier to understand, develop, and maintain distributed systems. As evidence that this argument is noncontroversial, consider that Kubernetes is today’s most popular framework for managing distributed applications and is increasingly seen as a sensible default choice for machine learning systems.1
Once we’ve accepted that most of the complexity of machine learning systems isn’t specific to machine learning, the really interesting remaining questions are about how machine learning systems can benefit from existing infrastructure, tools, and techniques – and about how to address the challenges that are unique to machine learning. For example:
- what additional complexity comes from failure modes that are characterized more by the divergence of probability distributions rather than by failed assertions or crossing clear performance thresholds?
- to what extent are traditional devops workflows and idioms appropriate for building and maintaining machine learning systems, and where do they break down?
- how can we address managing the complexity of entire machine learning systems rather than individual components?
- how can we make contemporary infrastructure more accessible to machine learning practitioners?
In order to evaluate how proposed solutions actually address these questions, it can be valuable to map out several aspects of machine learning systems:
- what human processes are involved in solving real problems with machine learning techniques?
- how do the diverse teams who build machine learning systems work and coordinate?
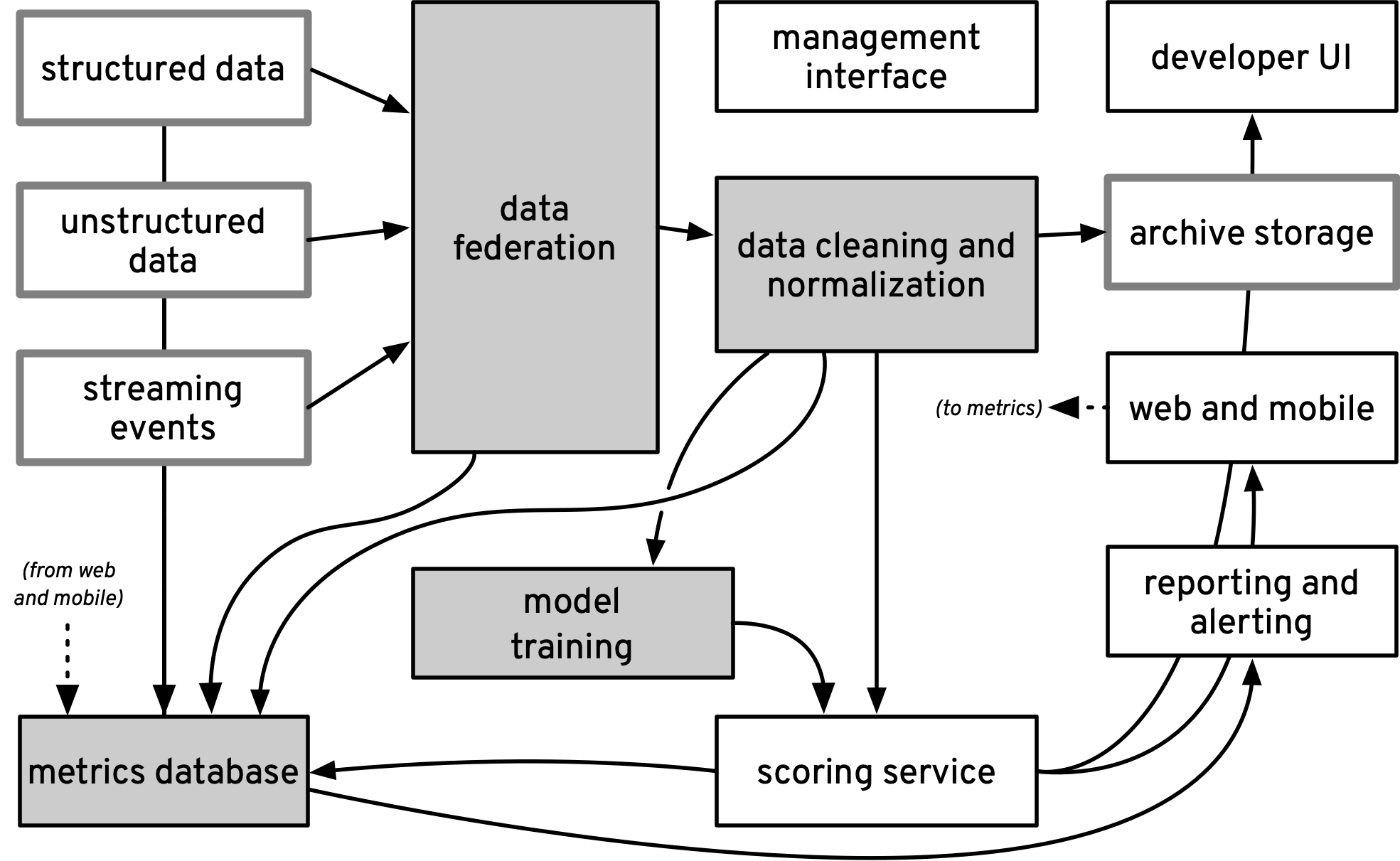
- what components comprise production machine learning systems, and how do they interact, both at a high level of abstraction (globally) and in fine detail (locally)?
{kind=link}
{kind=link}
The fact that these maps apparently overlap to some extent can be a source of confusion. A team of data scientists may have a feature engineering specialist and a modeling specialist. A production training pipeline may have feature extraction and model training components. While these different parts may connect together in analogous ways, they are not the same; our maps of systems, human processes, and organizations should each reveal different details of how we should support machine learning systems and the humans who build and maintain them.
The value of maps is as much in what they omit as it is in what they include: a good map will show the important details to navigate a given situation without including irrelevant details that obscure the presentation. By looking at these maps and identifying what areas of each are addressed by given solutions, it becomes easier to understand the strengths and shortcomings of various approaches. Ideally, a solution should address both complete workflows (human processes and interactions) and complete systems (software components and interactions).
Some solutions only support particular workloads, like particular training or inference frameworks, but not entire systems. Perhaps an “end-to-end” framework only addresses part of the problem, like model operationalization or data versioning – this will be obvious if we ascribe aspects of the solution to features of our map. Some solutions offer impressive demos but don’t address the problems our organization actually faces2 – again, this will be obvious by placing the solutions on our maps. Some tools that are ostensibly targeted for one audience have user experience assumptions that strongly imply that the developer had a different audience in mind, like “data science” tools that expect near-prurient interest in the accidental details of infrastructure3 – this will be obvious if we consider the interfaces of the tools corresponding to different map features in light of the humans responsible for these parts of our map. Perhaps a particular comprehensive solution only makes sense if organizations adopt an idiosyncratic workflow – this will be obvious because the solution will include some features that our map doesn’t and omit some features that our map includes.
Transit maps, which typically show the connections between lines and stations as a stylized graph, rather than aiming for geographical accuracy, present a particularly useful framework for understanding machine learning systems. In addition to capturing the components (stations or stops) and kinds of interactions (lines), other details like the existence of transfer stations and fare zones can expose other interesting aspects of the problem space. Here’s such a map that I designed to capture typical machine learning systems:
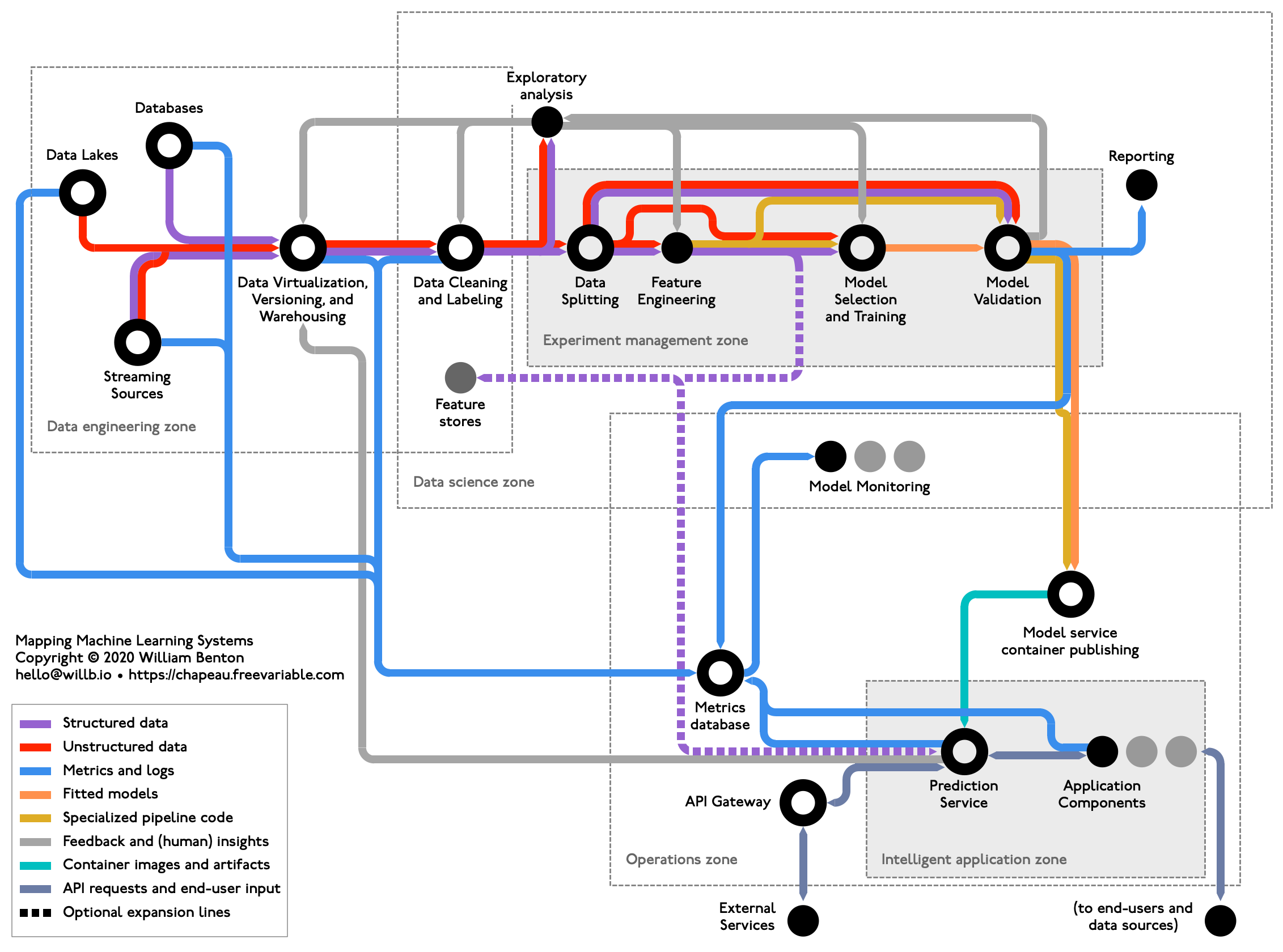
This map supports the story that Sophie Watson and I will be telling in our session at KubeCon North America next month – we’ll begin with the premise that Kubernetes is the right place to start for managing machine learning systems and then talk about some of the challenges unique to machine learning workflows and systems that Kubernetes and popular machine learning frameworks targeting Kubernetes don’t address. I hope you’ll be able to (virtually) join us!
Footnotes
You can see my version of the argument for machine learning on Kubernetes in this 2017 Berlin Buzzwords talk or in this 2020 IEEE Software article.↩︎
For more on this widespread issue, see my talk from Berlin Buzzwords 2019.↩︎
Many tools developed by and for the Kubernetes community are guilty of this shortcoming in that they assume, for example, that an end-user is as excited about the particular structure of a tool’s YAML files as its developers were.↩︎